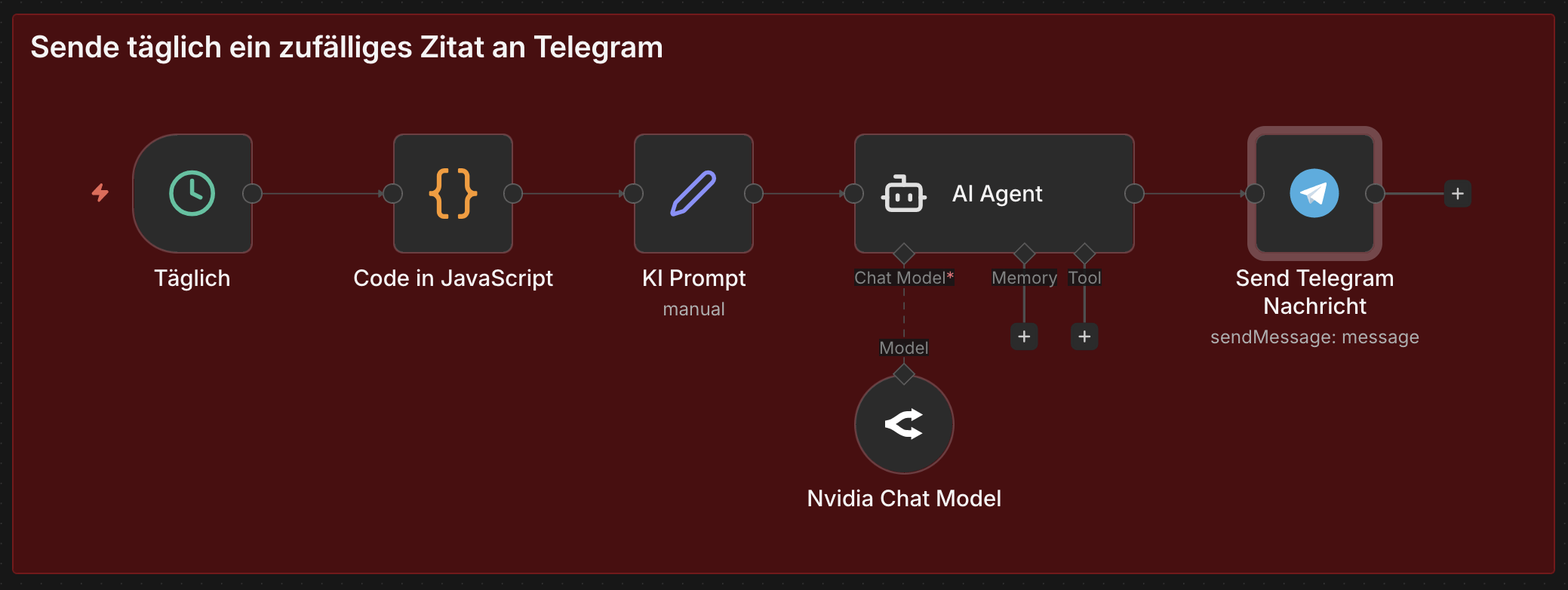
n8n Workflow: Tägliches KI-Zitat per Telegram
Dieser n8n-Workflow generiert täglich automatisiert ein Zitat einer echten historischen Person und versendet es an einen Telegram-Chat. Der Workflow kombiniert einen zeitgesteuerten Trigger, JavaScript-basierte Zufallslogik, einen KI-gestützten Agenten über die OpenRouter-Schnittstelle sowie die Telegram Bot API.
Der Ablauf gliedert sich in vier aufeinanderfolgende Phasen:
- Zeitgesteuerte Auslösung (täglich um 09:17 Uhr)
- Generierung einer zufälligen historischen Epoche
- KI-gestützte Zitaterstellung über ein großes Sprachmodell
- Versand des Zitats als Telegram-Nachricht
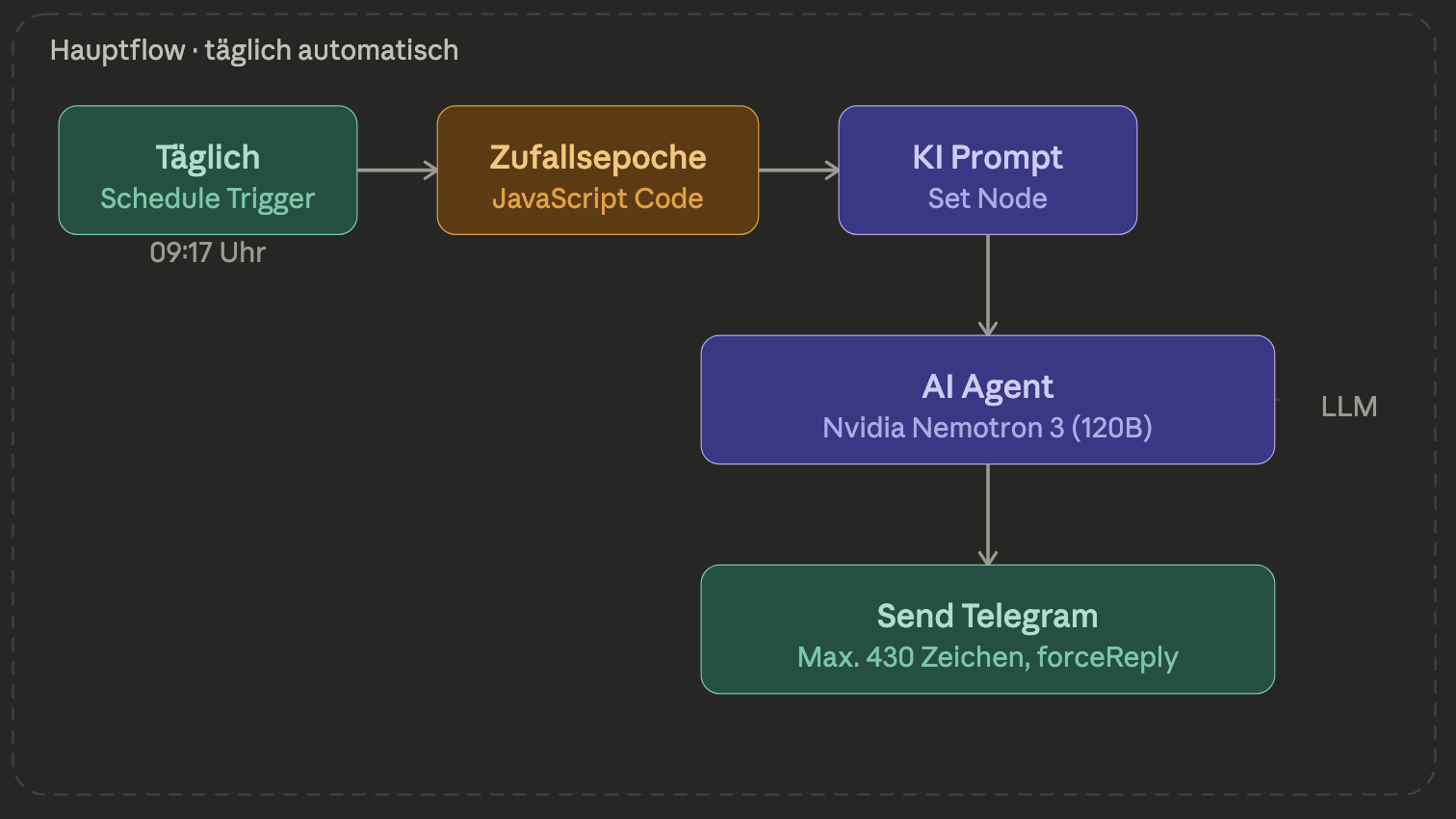
Technische Rahmenbedingungen
| Eigenschaft | Wert |
|---|---|
| Workflow-Status | Aktiv |
| Ausführungsreihenfolge | v1 |
| MCP-Verfügbarkeit | Deaktiviert |
| KI-Modell | Nvidia Nemotron 3 Super 120B (via OpenRouter, kostenlos) |
| KI-Plattform | OpenRouter API |
| Ausgabekanal | Telegram Bot API |
| Trigger-Zeitpunkt | Täglich 09:17 Uhr |
| Max. Nachrichtenlänge | 430 Zeichen |
Node-Beschreibungen
1. Täglich – Schedule Trigger
Typ: n8n-nodes-base.scheduleTrigger
Der Einstiegspunkt des Workflows. Der Schedule Trigger löst den gesamten Prozess täglich um 09:17 Uhr aus. Er übergibt keine Nutzdaten an den nächsten Node, sondern signalisiert lediglich den Startimpuls für die nachfolgende Pipeline.
Konfiguration: triggerAtHour: 9, triggerAtMinute: 17
2. Code in JavaScript – Zufällige Epoche
Typ: n8n-nodes-base.code (JavaScript, Version 2)
Dieses Node führt JavaScript-Code aus und berechnet die zeitliche Grundlage für das spätere Zitat. Die Logik arbeitet wie folgt:
- Ein zufälliges Geburtsjahr wird im Bereich 1700–2000 ermittelt.
- Eine zufällige Lebensspanne von 20–80 Jahren wird berechnet.
- Das Sterbejahr ergibt sich als Summe, gekappt auf maximal 2025.
Hier der JavaScript-Code:
|
1 2 3 4 5 6 7 8 9 10 11 |
// Zufälliges Geburts- und Sterbejahr generieren const gebJahr = Math.floor(Math.random() * (2000 - 1700 + 1)) + 1700; const lebensspanne = 20 + Math.floor(Math.random() * 61); // 20-80 Jahre const sterbJahr = Math.min(gebJahr + lebensspanne, 2025); return [{ json: { jahre: `${gebJahr}-${sterbJahr}`, jahrePrompt: `aus der Zeit ${gebJahr}-${sterbJahr}` } }]; |
Das Ausgabe-Objekt enthält zwei Felder:
- jahre – Jahreszeitraum im Format „1844-1900″
- jahrePrompt – Formulierung für den Prompt, z. B. „aus der Zeit 1844-1900″
3. KI Prompt – Set Node
Typ: n8n-nodes-base.set (Version 3.4)
Dieses Set-Node konstruiert aus den berechneten Epochendaten einen vollständigen deutschen LLM-Prompt. Der Prompt gibt dem Sprachmodell folgende Vorgaben:
- Es soll ein Zitat generiert werden, das von einer echten historischen Person aus der berechneten Epoche stammen könnte.
- Das Ausgabeformat ist exakt vorgegeben: „Zitattext.“ – ECHTER Name (Jahreszahlen)
- Keine Einleitungen, Erklärungen oder fiktive Personen sind erlaubt.
- Die Gesamtlänge des Ausgabetexts ist auf unter 440 Zeichen begrenzt.
Im Prompt sind Beispielpersonen für verschiedene Epochen eingebettet (z. B. Voltaire, Kant, Nietzsche, Einstein), um dem Modell eine stilistische Orientierungshilfe zu geben.
Ausgabe-Feld: chatInput
4. AI Agent + Nvidia Chat Model – KI-Generierung
Typ (Agent): @n8n/n8n-nodes-langchain.agent (Version 3.1)
Typ (Modell): @n8n/n8n-nodes-langchain.lmChatOpenRouter
Modell: nvidia/nemotron-3-super-120b-a12b:free
Der AI Agent empfängt den fertigen Prompt und sendet ihn über die OpenRouter-API an das Nvidia Nemotron 3 Super Modell mit 120 Milliarden Parametern. Dieses Modell ist über OpenRouter kostenlos verfügbar und generiert das eigentliche Zitat gemäß den vorgegebenen Regeln.
Das Ergebnis wird im Ausgabefeld output gespeichert und direkt vom nachfolgenden Telegram-Node weiterverwendet. Das Modell agiert ohne zusätzliche Tools oder Memory – die Generierung erfolgt rein auf Basis des übergebenen Prompts.
5. Send Telegram Nachricht – Ausgabe
Typ: n8n-nodes-base.telegram (Version 1.2)
Das generierte Zitat wird an einen festgelegten Telegram-Chat gesendet. Der Text wird auf maximal 430 Zeichen begrenzt, um innerhalb der Telegram-Nachrichtenlimits zu bleiben.
Besonderheiten der Konfiguration:
- replyMarkup: forceReply – Der Bot signalisiert, dass eine Antwort des Nutzers erwartet wird. Dies ist in Gruppenkonversationen nützlich, um den Gesprächskontext zu verknüpfen.
- appendAttribution: false – Die automatische n8n-Signatur wird nicht an die Nachricht angehängt.
Vollständiger Ablauf
| Schritt | Node | Aktion |
|---|---|---|
| 1 | Täglich | Löst den Workflow täglich um 09:17 Uhr aus |
| 2 | Code in JavaScript | Berechnet zufälliges Geburts- und Sterbejahr (1700–2025) |
| 3 | KI Prompt | Erstellt den deutschen LLM-Prompt mit Epochenbezug |
| 4 | AI Agent | Sendet Prompt an Nvidia Nemotron 3 (120B) via OpenRouter |
| 5 | Send Telegram | Sendet das Zitat (max. 430 Zeichen) an den Telegram-Chat |
Hinweise zur Weiterentwicklung
- Modellwahl: Das kostenlose Nvidia-Modell kann jederzeit durch ein anderes OpenRouter-Modell ersetzt werden, um Qualität oder Stil der Zitate anzupassen.
- Epochenfilterung: Der JavaScript-Code kann erweitert werden, um bestimmte Zeiträume gezielt einzuschließen oder auszuschließen.
- Fehlerbehandlung: Aktuell enthält der Workflow keine explizite Fehlerbehandlung. Ein Error-Trigger-Node könnte Fehlschläge protokollieren oder einen Neuversuch auslösen.
- Mehrsprachigkeit: Der Prompt ist auf Deutsch formuliert. Eine Anpassung für andere Sprachen ist durch einfache Änderung des Prompt-Textes möglich.
- Archivierung: Generierte Zitate könnten zusätzlich in einer Datenbank oder einem Google Sheet gespeichert werden, um Duplikate zu vermeiden.