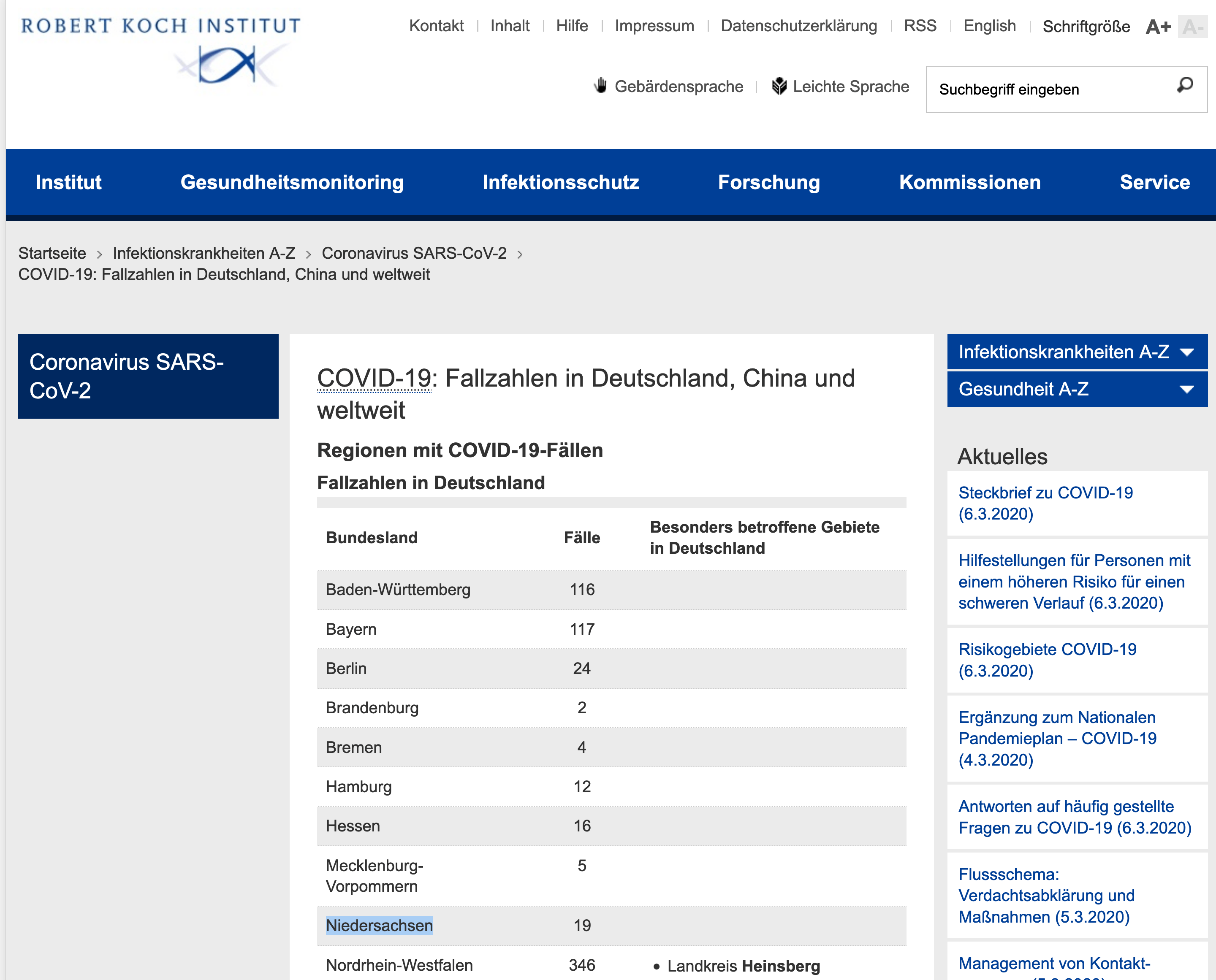
Das Robert Koch Institut (RKI) liefert für Deutschland aktuelle Corona-Fall-Zahlen auf dieser Webseite:
https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Fallzahlen.html
in einer schönen Tabelle die wir mit Jsoup abfragen wollen.
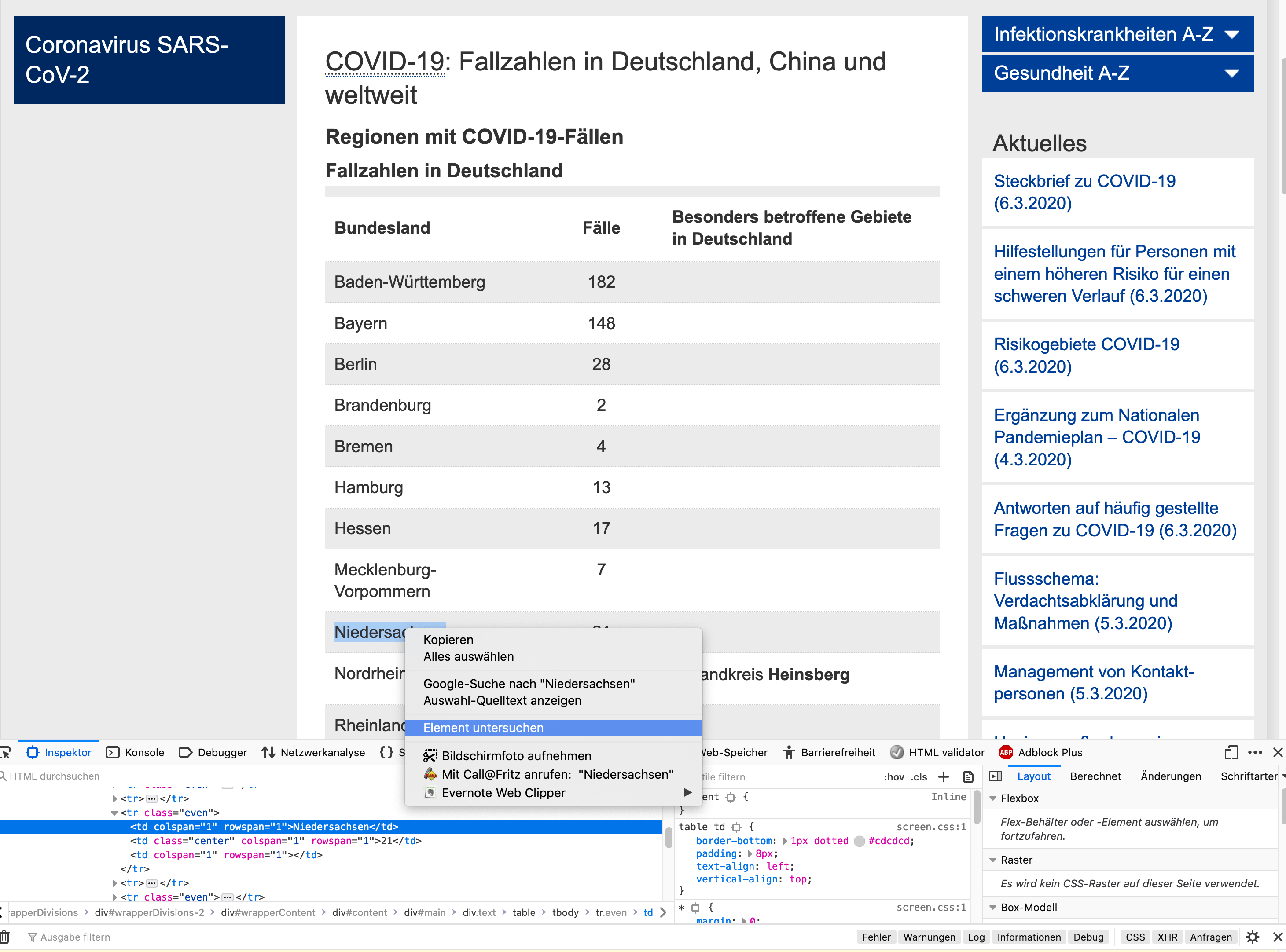
Wir schauen uns erst einmal die Stuktur der Seite an. D.h. wir markieren z.B. Niedersachsen und öffnen das rechte Kontexmenü und klicken auf „Element untersuchen“. Nun wird unten der HTML-Quelltext angezeigt. Wir sehen das die Tabelle, an der ersten stelle steht, und mit den tr und td Tags erstellt ist. Das müssen wir für die Analyse wissen.
Hier nun der kommentierte Beispiel-Code: „Wie können mit Java automatisch Webseiten mit Jsoup am Beispiel Corona abgefragt werden?“ weiterlesen