Will man schnell und einfach HTML-Dateien parsen bzw. auswerten, geht das mit der schönen JSoup-Api. Hier gibt es eine Mindmap für den schnellen Überblick.
Es sind dann nur zwei Zeilen nötig um z.B. den Titel einer Webseite einzulesen:
|
|
Document doc = Jsoup.connect("http://reise.wenzlaff.de/reisetabelle/").get(); System.out.println("Der Titel der Website: " + doc.title()); |
Hier mal ein Zitat aus der Orginal Api-Beschreibung:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
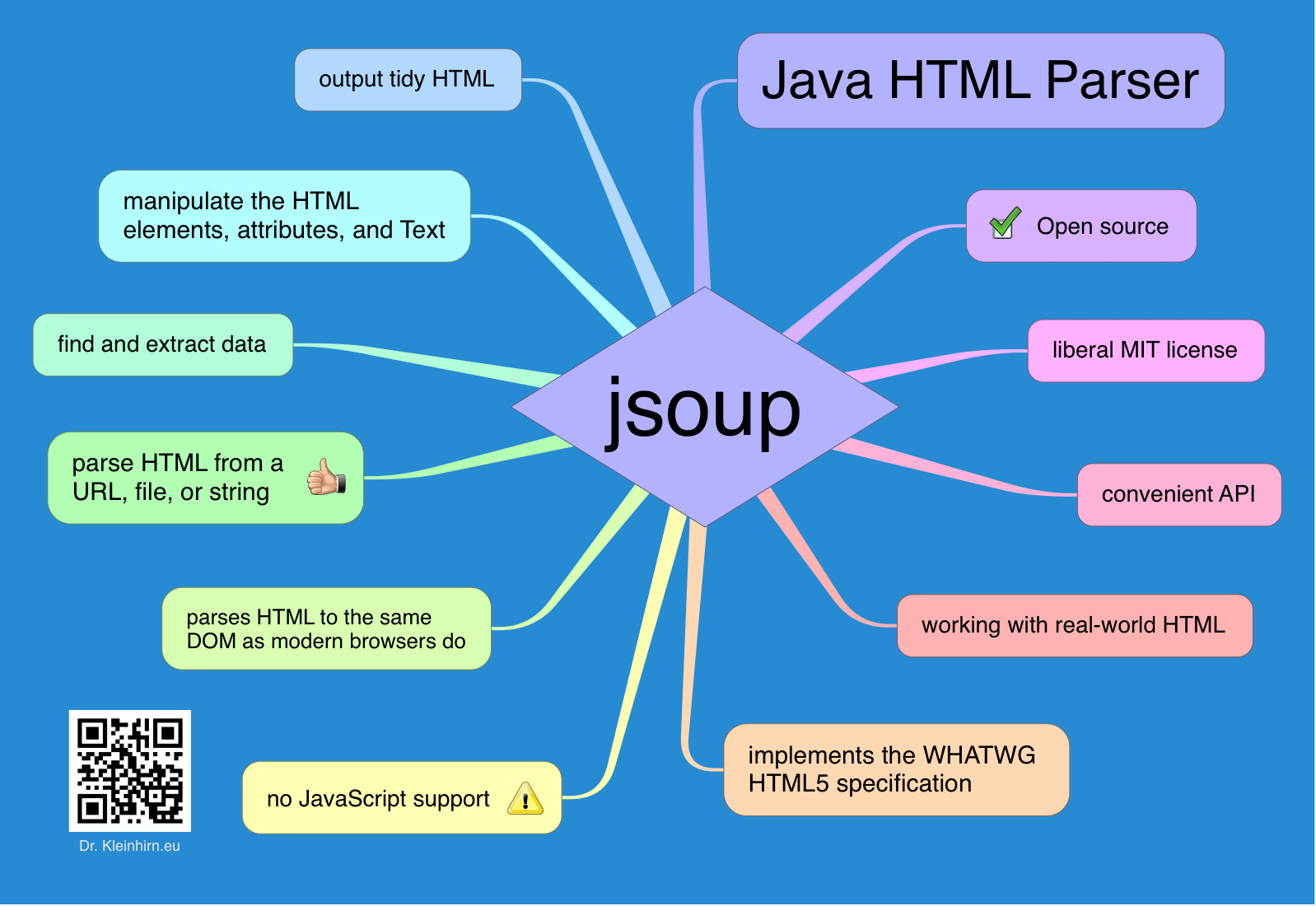
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for extracting and manipulating data, using the best of DOM, CSS, and jquery-like methods. jsoup implements the WHATWG HTML specification, and parses HTML to the same DOM as modern browsers do. parse HTML from a URL, file, or string find and extract data, using DOM traversal or CSS selectors manipulate the HTML elements, attributes, and text clean user-submitted content against a safe white-list, to prevent XSS output tidy HTML jsoup is designed to deal with all varieties of HTML found in the wild; from pristine and validating, to invalid tag-soup; j soup will create a sensible parse tree. |
Das sind doch Gründe!
Es braucht in der pom.xml des Maven Projekte nur diese eine Abhängigkeit angegeben zu werden: „Java: Parsen von HTML-Dateien mit JSoup 1.9.2 in zwei Java Zeilen“ weiterlesen
 Dazu einfach in der pom.xml:
Dazu einfach in der pom.xml: