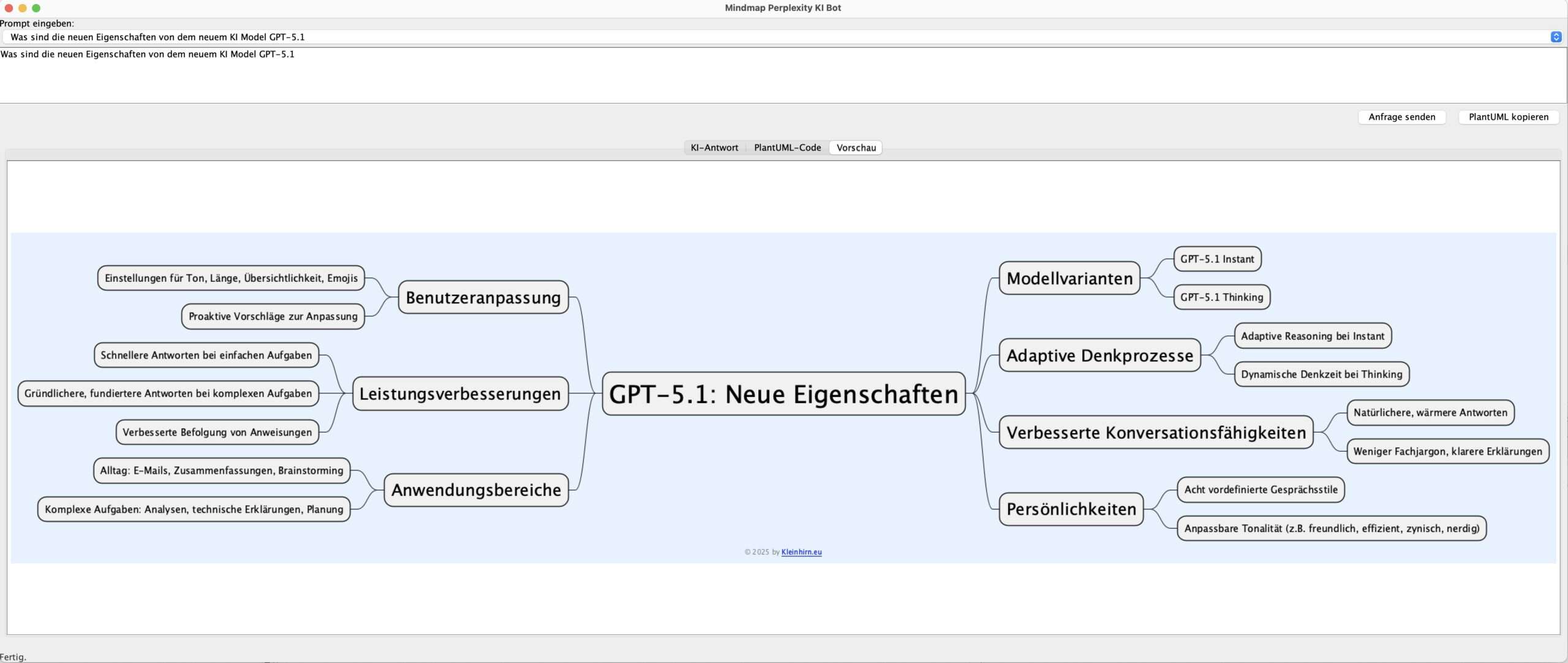
Die drei herausragenden Neuerungen von GPT‑5.1 sind
-die dualen Betriebsmodi (Instant vs. Thinking),
-das adaptive Reasoning (dynamische „Denkzeit“) und
-deutlich verbesserte Personalisierung inklusive Ton‑/Stilkontrolle.
Dazu mal den Mindmap-Generator um eine History ergänzt, und das neue Modell verwendet. Um das neue GPT‑5.1‑Modell zu wählen, musst du nicht den model‑Key ändern, sondern ein anderes Feld im Payload setzen – der model‑Wert bleibt für die Perplexity‑API weiterhin „sonar-pro“.
Perplexity nutzt im API‑Request das Feld model zur Auswahl der Perplexity‑eigenen Modelle wie „sonar-pro“, „sonar-deep-research“ oder „sonar-reasoning-pro“. Welches konkrete OpenAI‑Backend (z. B. GPT‑5.1 Instant oder GPT‑5.1 Thinking) dahinter verwendet wird, wird serverseitig über Konfigurationen deines Pro/Max‑Accounts bzw. über zusätzliche Optionsfelder gesteuert, nicht über den model‑String selbst.
Aktuell ist öffentlich dokumentiert, dass „sonar-pro“ einfach das „Advanced Search / Reasoning“-Modell von Perplexity adressiert; für GPT‑5.1 gibt es keinen neuen, separaten Modellnamen im Sinne von „gpt-5.1“ in der Perplexity‑API, sondern es wird als Upgrade hinter den bestehenden Pro‑Modellen ausgerollt. Dann eben nur die History-Funktion ergänzt.