TWRestMindmap mit React, Patternfly, RESTEasy, Swagger-UI, Quarkus, Panache, ORM, JPA, Hibernate, Docker und PostgreSQL DB verwenden. Um nicht JUnit 5 zu vergessen.
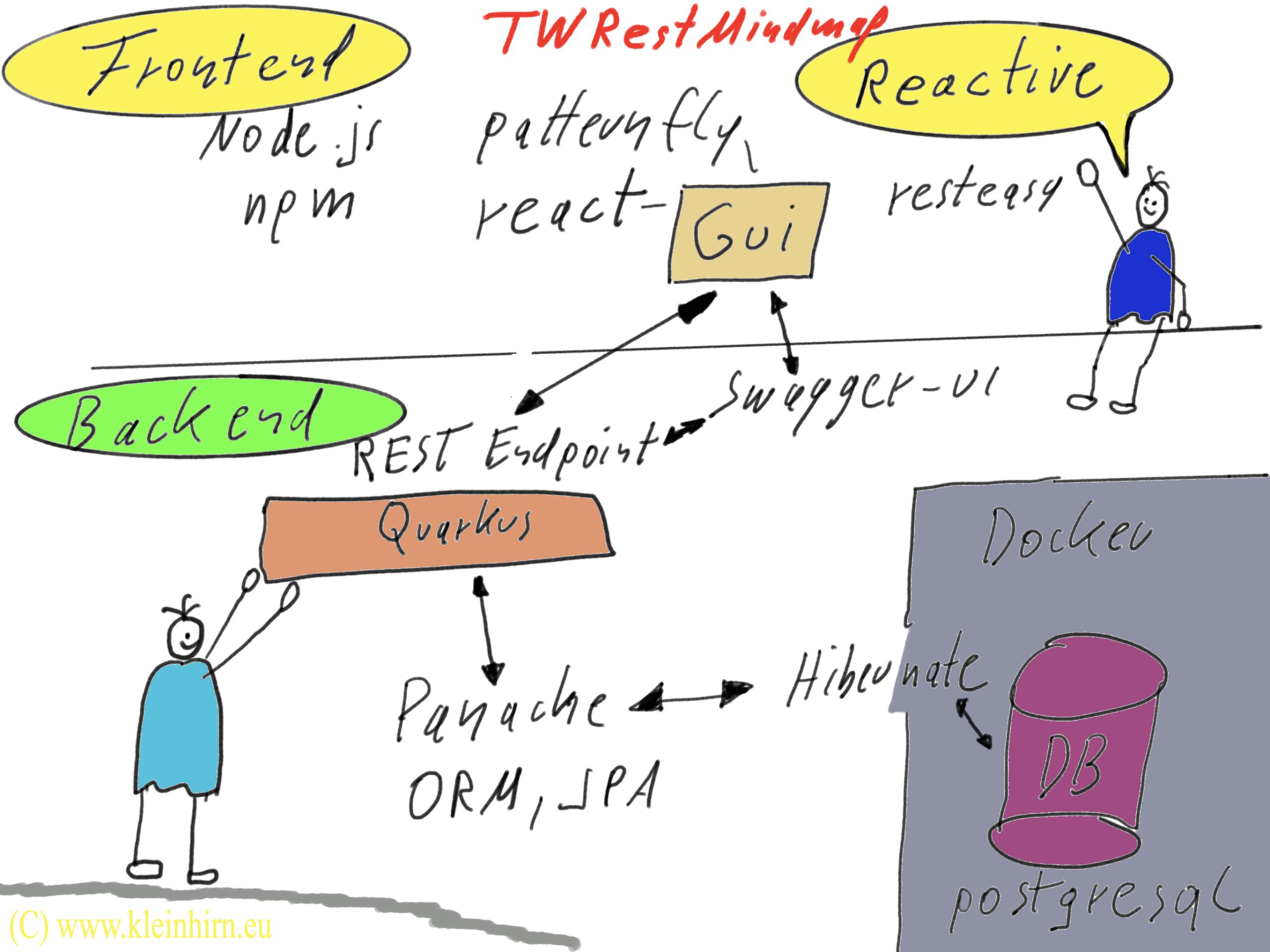
Wir bauen nun mit Quarkus eine React Anwendung die Titel und das Datum von Mindmaps anzeigt und per REST bedient werden kann. Die GUI im Browser sieht dann so aus: „TWRestMindmap mit React, Patternfly, RESTEasy, Swagger-UI, Quarkus, Panache, ORM, JPA, Hibernate, Docker und PostgreSQL“ weiterlesen